Introducing Swift Distributed Actors

We’re thrilled to announce a new open-source package for the Swift on Server ecosystem, Swift Distributed Actors, a complete server-oriented cluster library for the upcoming distributed actor language feature!
This library provides a complete solution for using distributed actors in server use-cases. By open-sourcing this project early, alongside the ongoing work on the language feature, we hope to gather more useful feedback on the shape of the language feature and associated transport implementations.
Distributed Actors Proposal
Distributed actors are an early and experimental language feature. We aim to simplify and push the state-of-the-art for distributed systems programming in Swift as we did with concurrent programming with local actors and Swift’s structured concurrency approach embedded in the language.
Currently, we are iterating on the design of distributed actors. We are looking to gather your feedback, use-cases, and general ideas in the proposal’s pitch thread, as well as the Distributed Actors category on the Swift forums. The library and language feature described in the proposal and this blog post are available in nightly toolchains, so please feel free to download them and get a feel for the feature. We will be posting updated proposals and other discussion threads on the forums, so if you are interested, please follow the respective category and threads on the Swift forums.
We are most interested in general feedback, thoughts about use cases, and potential transport implementations you would be interested in taking on. As we mature and design the language feature, the library (introduced below) will serve as the reference implementation of one such advanced and powerful actor transport. If you are interested in distributed systems, contributions to the library itself are also very welcome, and there is much to be done there as well!
Soon, we will also provide a more complete “reference guide,” examples, and article-style guides. These materials, to be authored using the recently open-sourced DocC documentation compiler, will teach about the specific patterns and use-cases this library enables.
These proposed language features–as all language features–will go through a proper Swift Evolution process before lifting their experimental status. We invite the community to participate and help us shape the language and APIs through review, contributions, and sharing experiences. Thank you very much in advance!
This project is released as “early preview” and all of its APIs are subject to change, or even removal without any prior warning.
The library depends on un-released, work-in-progress, and Swift Evolution review pending language features. As such, we cannot recommend using it in production just yet — the library may depend on specific nightly builds of toolchains, etc.
The primary purpose of open sourcing this library early is to prove the ability to implement a feature-complete, compelling clustering solution using the distributed actor language feature and co-evolving the two in tandem.
Distributed Actors Overview
Distributed actors are the next step in the evolution of Swift’s concurrency model.
With actors built into the language, Swift offers developers a safe and intuitive concurrency model that is an excellent fit for many applications. Thanks to advanced semantic checks, the compiler can guide and help developers write programs free from low-level data races. These checks are not where the usefulness of the actor model ends, though: unlike other concurrency models, the actor model is also tremendously valuable for modeling distributed systems. Thanks to the notion of location transparent distributed actors, we can program distributed systems using the familiar idea of actors and then readily move it to a distributed, e.g., clustered, environment.
With distributed actors, we aim to simplify and push the state of the art of distributed systems programming, the same way we did with concurrent programming with local actors and Swift’s structured concurrency models embedded in the language.
This abstraction does not intend to completely hide away the fact that distributed calls are crossing the network, though. In a way, we are doing the opposite and programming assuming that calls may be remote. This small yet crucial observation allows us to build systems primarily intended for distribution and testable in local test clusters that may even efficiently simulate various error scenarios.
Distributed actors are similar to (local) actors because they encapsulate their state with communication exclusively through asynchronous calls. The distributed aspect adds to that equation some additional isolation, type system, and runtime considerations. However, the surface of the feature feels very similar to local actors. Here is a small example of a distributed actor declaration:
// **** APIS AND SYNTAX ARE WORK IN PROGRESS / PENDING SWIFT EVOLUTION ****
// 1) Actors may be declared with the new 'distributed' modifier
distributed actor Worker {
// 2) An actor's isolated state is only stored on the node where the actor lives.
// Actor Isolation rules ensure that programs only access isolated state in
// correct ways, i.e. in a thread-safe manner, and only when the state is
// known to exist.
var data: SomeData
// 3) Only functions (and computed properties) declared as 'distributed' may be accessed cross actor.
// Distributed function parameters and return types must be Codable,
// because they will be crossing network boundaries during remote calls.
distributed func work(item: String) -> WorkItem.Result {
// ...
}
}
Distributed actors take away a lot of the boilerplate that we’d typically have to build and re-invent every time we create some distributed RPC system. After all, we did not care in the snippet about exact serialization and networking details; we declared what we needed to get done and sent work requests across the network! This omission of boilerplate is quite powerful, and we hope you’ll enjoy using actors in this capacity, in addition to their concurrency aspect.
To have a distributed actor participate in some distributed system, we must provide it with an ActorTransport, a user-implementable library component responsible for performing all the networking necessary to make remote function calls. Developers offer their transport of choice during the instantiation of a distributed actor, like this:
// **** APIS AND SYNTAX ARE WORK IN PROGRESS / PENDING SWIFT EVOLUTION ****
// 4) Distributed actors must have a transport associated with them at initialization
let someTransport: ActorTransport = ...
let worker = Worker(transport: someTransport)
// 5) Distributed function invocations are asynchronous and throwing, when performed cross-actor,
// because of the potential network interactions of such call.
//
// These effects are applied to such functions implicitly, only in contexts where necessary,
// for example: when it is known that the target actor is local, the implicit-throwing effect
// is not applied to such call.
_ = try await worker.work(item: "work-item-32")
// 6) Remote systems may obtain references to the actor by using the 'resolve' function.
// It returns a special "proxy" object, that transforms all distributed function calls into messages.
let result = try await Worker.resolve(worker.id, using: otherTransport)
This post summarizes the distributed actor feature at a very high level. We encourage those interested to read the full proposal available in Swift Evolution, and provide feedback or ask questions in the Distributed Actors category on the Swift Forums.
You can follow along and provide feedback on the distributed actor language proposal on the Swift forums and Swift Evolution. The current, complete draft is also available for review, though we expect to make significant changes to it shortly.
We would love to hear your feedback and see you participate in the Swift Evolution reviews of this exciting new feature!
Distributed Actor Transport Implementations
The Swift standard library itself does not provide any specific transport. Instead, it focuses on defining the language model and extension points that transport implementations can use to implement particular transports for distributed actors.
We intend to enable new and exciting transport implementations. The standard library defines an ActorTransport protocol, which anyone may implement to utilize distributed actors in unique and compelling use cases. Examples of potential transport implementations include, but are not limited to, clustered systems, web-socket-based messaging, or even inter-process communication for distributed actors.
Building an actor transport is not a trivial task, and we only expect a handful of mature implementations to take the stage eventually.
Introducing: Distributed Actors Cluster Transport
Today, we are announcing the open source release of the Swift Distributed Actors library - a fully featured framework for building distributed systems Swift. It is an implementation of the above mentioned ActorTransport protocol, and can serve as a reference implementation for other transport authors.
This cluster library is focused on server-side peer-to-peer systems, which are often used in systems which require “live” interactions with multiple parties, such as: presence systems, game lobbies, monitoring or IoT systems, and classical “control plane” systems such as orchestrators, schedulers, etc.
The library makes use of SwiftNIO, Swift’s high-performance server-side focused networking library, to implement the cluster’s networking layer. The cluster also provides a membership service, based on the Swift Cluster Membership library which was open sourced earlier last year. This means you can use this cluster in a stand-alone mode, without needing to spin up additional service discovery or database services. We believe this is an important capability as it simplifies deployment in some bare-metal scenarios, and makes utilizing this cluster technology viable in others where it otherwise might not have been possible due to resource constraints.
The cluster is designed to be very extensible, and it is possible to bring your own implementations of most of the core components, including node discovery, failure detection and more.
The distributed actor system enables actors to form a cluster, discover each other and communicate with one another without the need for low-level network programming that would otherwise be necessary. In the next sections we’ll showcase some of the basic steps one would take to build such distributed actor system.
Forming Clusters
For distributed actors to live up to their name, let us focus on a multi-node scenario right away. We’ll start two nodes and have them form a cluster. The code snippets perform this task in one and the same process, but of course the intent of such system is to eventually run across multiple independent machines. Doing so isn’t all that different, and we’ll discuss this a bit later.
The ability to create multiple cluster nodes in the same process highlights another useful capability of the cluster: it is possible to write your distributed system tests in-process, and either have them communicate in memory or communicate over an actual network - the only difference between those two cases is the transport passed to each actor. This allows us to develop distributed actors once, and then test, run, and deploy the same code but in slightly different configurations. We can run the same set of distributed actors in either:
- single node cluster, using a single process - only pretending to be distributed, which can be useful for early and local development,
- multiple cluster nodes, but sharing the same process - which is useful in testing, as we can write unit tests for our distributed system, and have it use the actual networking, or even a transport simulating message loss or delays,
- multiple cluster nodes, on actual different physical machines - which is the usual deployment strategy for such systems in production.
Forming clusters needs some knowledge about where other nodes of the clusters can be found. First, let us show the same-process but many nodes way of forming a cluster, as this is what one frequently uses in local testing:
// **** APIS AND SYNTAX ARE WORK IN PROGRESS / PENDING SWIFT EVOLUTION ****
let first = ActorSystem("FirstNode") { settings in
settings.cluster.enable(host: "127.0.0.1", port: 7337)
}
let second = ActorSystem("SecondNode") { settings in
settings.cluster.enable(host: "127.0.0.1", port: 8228)
}
first.cluster.join(host: "127.0.0.1", port: 8228)
// or convenience API for local testing:
// first.cluster.join(node: second.settings.cluster.node)
The actor system exposes many useful functions regarding the cluster state and actions it can perform via the .cluster property, such as joining other nodes into the cluster.
If the cluster already has multiple nodes, it is only necessary for a single node to join a new node for all the other nodes to eventually learn about this new node. Membership information is gossiped throughout the cluster automatically.
In a production system, we wouldn’t be hardcoding the joining process like this. Production deployments usually have some form of service discovery of nodes available, and thanks to Swift Service Discovery we can easily utilize those to discover and automatically join nodes into our cluster. Swift Service Discovery provides an abstract API over discovery mechanisms, and can support backends such as DNS records or Kubernetes service discovery. We could use a hypothetical DNS discovery mechanism to discover the nodes:
// **** APIS AND SYNTAX ARE WORK IN PROGRESS / PENDING SWIFT EVOLUTION ****
let third = ActorSystem("Third") { settings in
settings.cluster.enable()
settings.cluster.discovery = ServiceDiscoverySettings(
SomeExistingDNSBasedServiceDiscovery(), // or any other swift-service-discovery mechanism
service: "my-actor-cluster" // `Service` type aligned with what DNSBasedServiceDiscovery expects
)
}
// automatically joins all nodes that DNSBasedServiceDiscovery finds for "my-actor-cluster"
This configuration would cause the system to periodically query DNS for service records and attempt joining any newly discovered nodes to our cluster.
Discovering Distributed Actors
A common question when first learning about distributed actors is “How do I find a remote actor?” since in order to obtain a remote reference, we need to obtain a specific ActorIdentity to be provided to the runtime, yet it is impossible to “just guess” the right identifier of a remote actor.
Thankfully, the cluster comes with a solution to this problem! We call it the Receptionist pattern - because similar to a hotel, actors need to check-in (and out) at the reception in order for others to be able to find them. This check-in is optional and not automatic, by design, as not all distributed actors necessarily want to advertise their existence to all other actors, but only to a few select ones they know and trust etc.
The receptionist is interacted with from both sides, the actor registering with it, and an actor who is interested in listening to updates of a specific reception key.
First, let’s see how a distributed actor can advertise itself in the cluster under a known reception key:
// **** APIS AND SYNTAX ARE WORK IN PROGRESS / PENDING SWIFT EVOLUTION ****
distributed actor FamousActor {
init(transport: ActorSystem) async {
await transport.receptionist.register(self, withKey: .famousActors)
}
}
extension DistributedReception.Key {
static var famousActors: Self<FamousActor> { "famous-actors" }
}
As we register a specific actor with the receptionist, it will automatically gossip this information across the network with other nodes in the cluster, and ensure all nodes are aware of this famous actor.
On other nodes of the cluster we can listen to updates about the famous actors key, and we’d simply be notified when new actors become known in the cluster. Here we use Swift’s AsyncSequence feature to consume this potentially infinite stream of updates:
// **** SYNTAX BASED ON CURRENT PROPOSAL TEXT AND LIBRARY -- NOT FINAL APIs ****
for try await famousActor in transport.receptionist.subscribe(.famousActors) {
print("Oh, a new famous actor appeared: \(famousActor.id)")
// we can use the famousActor right away and send messages to it
}
It is also possible to ask the receptionist for a single, or all actors known under a specific key, rather than subscribing to updates.
The receptionist pattern gives us a type-safe way to advertise and discover actors, without having to worry about the exact networking details of how we’d achieve this.
Reacting to Cluster and Actor Lifecycle Events
The cluster provides the ability to reason about the lifecycle of actors, regardless if they are co-located on the same, or on some remote compute node. This feature is surfaced as allowing distributed actors to “watch” each other for termination.
Whenever a watched actor is deinitialized, or the node on which it was running is determined “down”, a terminated signal is emitted about this actor, to any actors which were watching its lifecycle. The cluster uses the Swift Cluster Membership library which was open sourced earlier last year to detect nodes failing, and it moves them along a lifecycle graph as shown below:
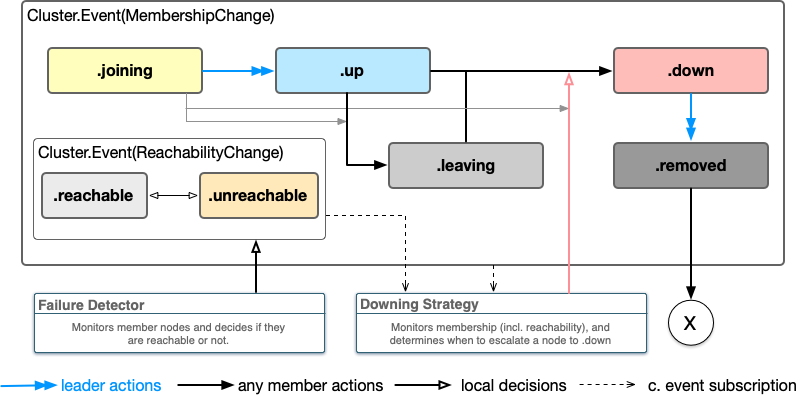
Cluster events are emitted as an AsyncSequence<Cluster.Event>. Such sequence always begins with a “snapshot” of the current state of the cluster, followed by any changes that occur since that moment. This could be used to implement a function that waits until the cluster reaches a certain size for example:
// **** APIS AND SYNTAX ARE WORK IN PROGRESS / PENDING SWIFT EVOLUTION ****
var membership: Membership = .empty
// "infinite" stream of cluster events
for try await event in system.cluster.events {
print("Cluster event: \(event)")
// events can be applied to membership to
try membership.apply(event)
if membership.count(atLeast: .up) > 3 { // membership has useful utility functions
break
}
}
We could also inspect the specific events if desired. Refer to the documentation of Cluster.Membership to learn more about all the types of events and information available to you about the cluster state.
This isn’t the level of API most developers will be interacting with though. The actor cluster automatically translates relevant events to actor lifecycle signals, so instead of listening for cluster events every time we want to monitor an actor’s lifecycle, we can monitor specific actors, and in case the entire node the actor was located on is terminated, we’ll get notified about that too. This feature is called LifecycleWatch and is used as follows:
// **** APIS AND SYNTAX ARE WORK IN PROGRESS / PENDING SWIFT EVOLUTION ****
// distributed actor Person {}
let other: Person
let system: ActorSystem
watchTermination(of: other) { terminatedIdentity in
system.log.info("Actor terminated: \(terminatedIdentity)"
}
It is important that the watch API does not retain the actor, and thus won’t keep it alive - otherwise the the termination would never be observed after all.
Distributed actors may need to keep themselves alive by storing strong references to them in some kind of “manager” actor, some registry, or having the receptionist retain them (e.g. until they unregister, or some other condition happens).
Example: Distributed Worker Pool
Finally, we can put all those features together and show how to build a sample distributed worker pool utilizing the actor cluster.
Thanks to the cluster’s service discovery and failure detection mechanisms, we do not need to implement anything special in order to add new nodes as they are added to the cluster, or remove them as they are terminated. Instead, we can focus on the actors themselves, as the cluster mechanisms will automatically translate cluster events into respective events about the distributed actors.
First, let us prepare a WorkerPool distributed actor. It will subscribe to the receptionist with a worker key, and add all workers which appear in the cluster to the pool. As they terminate, it removes them from the pool it maintains.
// **** APIS AND SYNTAX ARE WORK IN PROGRESS / PENDING SWIFT EVOLUTION ****
extension Reception.Key {
static var workers: Self<Worker> { "workers" }
}
distributed actor WorkerPool {
var workers: Set<Worker> = []
init(transport: ActorSystem) async {
Task {
for try await worker in transport.receptionist.subscribe(.workers) {
workers.insert(worker)
watchTermination(of: worker) {
workers.remove($0) // thread-safe!
}
}
}
}
distributed func submit(work item: WorkItem) async throws -> Result {
guard let worker = workers.shuffled.first else {
throw NoWorkersAvailable()
}
try await worker.work(on: item)
}
}
The WorkerPool also reaps the usual benefits from being an actor, in addition to being a distributed actor: we can safely modify the workers variable without having to care or worry about threading — the actor guarantees the concurrency safety of this property thanks to actor isolation.
The worker pool uses two cluster features: the receptionist to discover new workers, and the lifecycle watching in order to remove them as they terminate. This is enough to implement a fully managed set of peers, that will be dynamically updated as worker nodes join and leave the cluster.
The worker implementation is pretty short as well. We need to ensure that all Worker actors register themselves with the receptionist as they become initialized, so we’ll do this in the actor’s asynchronous initializer. We don’t need to do anything else for the receptionist to automatically make a reference to this worker available in the cluster. When the worker deinitializes, or the entire node it was running on crashes, the receptionists on the other systems will automatically translate this into termination signals on their respective systems.
// **** APIS AND SYNTAX ARE WORK IN PROGRESS / PENDING SWIFT EVOLUTION ****
distributed actor Worker {
init(transport: ActorSystem) async {
await transport.receptionist.register(self, withKey: .workers)
}
distributed func work(on item: WorkItem) async -> Result {
// do the work
}
}
That’s it! The receptionist will automatically gossip with other peers in the cluster about the new worker instance joining the reception under the workers key. Any other actor in the cluster which subscribes to the receptionist’s updates can then discover these actors and contact them.
You also may have noticed that we did not have to deep dive into implementing any networking, request/reply matching or even any encoding/decoding from some wire format. All this is handled by the language feature in collaboration with the ActorSystem transport implementation. There are ways to customize many aspects of these, however in the simple case — we don’t need to worry about it!
So, other than the system initialization (configuring node discovery), this really is all the code you need to write to prepare a distributed worker pool. We hope this small example has inspired you and given you a rough idea what kinds of use cases this feature enables. There is much more to learn and discover about distributed actors, but for now we’ll leave it at that.